Motivation
Among the challenges that our engineering team faces is the ability to classify an email-sending entity as a forwarder. At Agari, we are primarily interested in the authentication of emails from originating senders. Forwarders are defined as entities which forward messages from originating senders as well as from other forwarders. Examples include servers in educational institutions, which often forward messages to students after they have graduated.
In the course of executing their forwarding roles, these entities can break email authentication, leading email recipients to incorrectly classify forwarded inbound email as “failed authentication”. This presents Agari with a noise problem — in this case, an email classified as “failed authentication” is not necessarily inauthentic. To correctly gauge the volume and causes of legitimately inauthentic emails, we need to remove this source of noise by classifying sending entities as forwarders. In this post, we focus on the assorted tools used to create a reliable forwarder classification model as well as the challenges encountered from a data science perspective.
Exploring Options
Like most classification problems, the general plan is to create a model which mimics the decisions an experienced person would make when observing the characteristics of a sender. However, there is no sizable labeled data set with which to train our model (the semantic equivalent of a human expert's knowledge and experience gained over time). This leaves us with a few options:
Manual labeling of enough data points to produce a reliable training set is infeasible. However, as mentioned later, there is promise in combining the manual tagging of data with the other methods mentioned here. Unsupervised learning schemes, although useful in certain contexts, come with caveats. In this case, the construction of features required for unsupervised learning may produce spurious separation of classes in the feature space, leading to a pair of classes that may not necessarily be “forwarder – non-forwarder.” Here at Agari, a company full of email professionals with many years of experience, we opt for the iterative approach which utilizes our internal knowledge bank.
Model Evolution
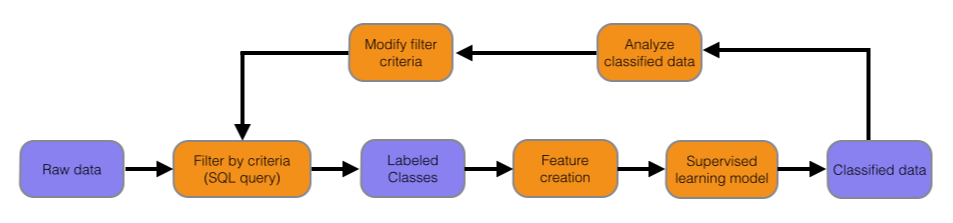
Early attempts at the model consisted of filtering the full set of data based upon simple criteria. Our live experts' statements of "these are some of the common criteria and behavior we see in forwarders" were simply translated to a SQL query. However, due to the complexity of behavior shown by senders, this method produces a significant level of false positives and negatives.

Since the query method produces a sizable, if not perfect, labeled data set, we set out to train a supervised learning algorithm. The idea is to create an iterative procedure which uses the output of the trained model to improve the initial query, which in turns improves the quality of the labeled training data.
This introduces the next major challenge: creating a set of relevant features from the raw data. In the context of machine learning applications, the number of uncorrelated features able to be extracted by the raw data is very small. In this case, feature engineering amounts to quantifying the behavior of forwarders as observed by humans. In addition, we can include more information by designing features which separate certain subclasses. One feature is designed to differentiate forwarders from internal infrastructure, another is designed to distinguish forwarders from botnets, and so on.
By observing aggregate information of the features for each class, and with a healthy amount of spot-checking, we realized that this method correctly classifies a significant amount of the false positives and negatives produced by the previous model. The information contained in the features for these data points were used to improve the initial labeled data set query, resulting in a feedback loop.
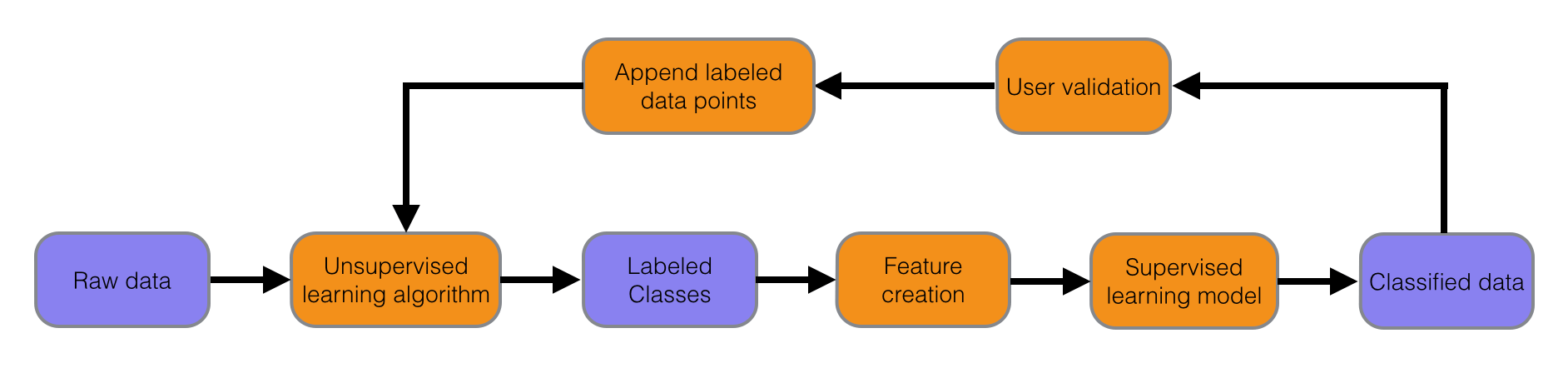
After a few iterations of this method, the model improves substantially from an aggregate point of view. But, once again, the lack of a labeled data set makes it difficult to assess its accuracy and quality with hard numbers. For this next step, we'll be crowdsourcing data labeling from our internal users. By creating a mechanism for Agarians to quickly label data points, we can supply validation for current and future models, create accuracy estimates, and provide the basis for a larger, and reliably-labeled, data set. This introduces a fourth bullet point to the above list:
This last point is a use case in which unsupervised learning algorithms could be useful. Given a set of labeled data points in feature space, a scheme such as Clustering or Expectation Maximization can not only provide more examples with which to train the supervised learning model, but may also drive the creation of new features which carry more information.
Moving Forward
Like all classification problems, there will always be room for improvement in accuracy and efficacy. The dynamic nature of email and the behavior of malicious entities means that the model will need to change over time. With a strong framework of feature extraction, learning schemes, and user feedback, we can be confident that our models will adapt appropriately over time. In addition, the challenges faced in this project are not unique to forwarder identification. A generalized model which combines the power of learning algorithms with the knowledge of subject matter experts can be applied even outside the domain of email security. At Agari, we use this combination of data science and knowledge harvesting to reach our goal of stopping the use of email as the primary vector for cyberattacks.
Among the challenges that our engineering team faces is the ability to classify an email-sending entity as a forwarder. At Agari, we are primarily interested in the authentication of emails from originating senders. Forwarders are defined as entities which forward messages from originating senders as well as from other forwarders. Examples include servers in educational institutions, which often forward messages to students after they have graduated.
In the course of executing their forwarding roles, these entities can break email authentication, leading email recipients to incorrectly classify forwarded inbound email as “failed authentication”. This presents Agari with a noise problem — in this case, an email classified as “failed authentication” is not necessarily inauthentic. To correctly gauge the volume and causes of legitimately inauthentic emails, we need to remove this source of noise by classifying sending entities as forwarders. In this post, we focus on the assorted tools used to create a reliable forwarder classification model as well as the challenges encountered from a data science perspective.
Exploring Options
Like most classification problems, the general plan is to create a model which mimics the decisions an experienced person would make when observing the characteristics of a sender. However, there is no sizable labeled data set with which to train our model (the semantic equivalent of a human expert's knowledge and experience gained over time). This leaves us with a few options:
- Manually label data points
- Utilize an unsupervised learning algorithm to split the data into separate classes
- Apply an iterative formula which combines the creation of a rough labeled data set with a supervised learning scheme
Manual labeling of enough data points to produce a reliable training set is infeasible. However, as mentioned later, there is promise in combining the manual tagging of data with the other methods mentioned here. Unsupervised learning schemes, although useful in certain contexts, come with caveats. In this case, the construction of features required for unsupervised learning may produce spurious separation of classes in the feature space, leading to a pair of classes that may not necessarily be “forwarder – non-forwarder.” Here at Agari, a company full of email professionals with many years of experience, we opt for the iterative approach which utilizes our internal knowledge bank.
Model Evolution
Early attempts at the model consisted of filtering the full set of data based upon simple criteria. Our live experts' statements of "these are some of the common criteria and behavior we see in forwarders" were simply translated to a SQL query. However, due to the complexity of behavior shown by senders, this method produces a significant level of false positives and negatives.
Since the query method produces a sizable, if not perfect, labeled data set, we set out to train a supervised learning algorithm. The idea is to create an iterative procedure which uses the output of the trained model to improve the initial query, which in turns improves the quality of the labeled training data.
This introduces the next major challenge: creating a set of relevant features from the raw data. In the context of machine learning applications, the number of uncorrelated features able to be extracted by the raw data is very small. In this case, feature engineering amounts to quantifying the behavior of forwarders as observed by humans. In addition, we can include more information by designing features which separate certain subclasses. One feature is designed to differentiate forwarders from internal infrastructure, another is designed to distinguish forwarders from botnets, and so on.
By observing aggregate information of the features for each class, and with a healthy amount of spot-checking, we realized that this method correctly classifies a significant amount of the false positives and negatives produced by the previous model. The information contained in the features for these data points were used to improve the initial labeled data set query, resulting in a feedback loop.
After a few iterations of this method, the model improves substantially from an aggregate point of view. But, once again, the lack of a labeled data set makes it difficult to assess its accuracy and quality with hard numbers. For this next step, we'll be crowdsourcing data labeling from our internal users. By creating a mechanism for Agarians to quickly label data points, we can supply validation for current and future models, create accuracy estimates, and provide the basis for a larger, and reliably-labeled, data set. This introduces a fourth bullet point to the above list:
- Implement a user validation feedback loop by allowing users to mark senders as forwarders or non-forwarders.
This last point is a use case in which unsupervised learning algorithms could be useful. Given a set of labeled data points in feature space, a scheme such as Clustering or Expectation Maximization can not only provide more examples with which to train the supervised learning model, but may also drive the creation of new features which carry more information.
Moving Forward
Like all classification problems, there will always be room for improvement in accuracy and efficacy. The dynamic nature of email and the behavior of malicious entities means that the model will need to change over time. With a strong framework of feature extraction, learning schemes, and user feedback, we can be confident that our models will adapt appropriately over time. In addition, the challenges faced in this project are not unique to forwarder identification. A generalized model which combines the power of learning algorithms with the knowledge of subject matter experts can be applied even outside the domain of email security. At Agari, we use this combination of data science and knowledge harvesting to reach our goal of stopping the use of email as the primary vector for cyberattacks.